-
카카오톡 인천대학교 학식봇 만들기(AWS Lambda, layer) - 7App 2021. 7. 9. 15:02
그저께에도 프로젝트는 계속해서 작업했지만, 포스팅을 하지 않았어서 그저께 진행한 진행사항을 묶어서 포스팅하게 됐다.
진행중인 학식봇에는 여러가지 기능을 구현할 계획이다.

학식봇의 블록(기능)들의 현황 현재 구현된 기능 : 날짜별 메뉴출력(daymenu_show)
앞으로 구현할 기능 : 특정 날짜, 특정 시간 메뉴 출력(typemenu_show) // ex) 7월 10일 중식 알려줘
먹었던 메뉴 저장(menu_save) - 히스토리 관리 기능 // ex) 오늘 중식 먹었어. -> 해당 날짜의 중식을 히스토리에 저장
현재 사용하고있는 AWS lambda를 통해 봇을 개발하려면, 각각의 기능마다 다른 lambda 함수를 사용해야한다.
그래서 crawling_INUmenu.py를 라이브러리처럼 여러 함수에서 참조해서 사용해야 하는데, 각각의 lambda 함수마다 똑같은 코드를 계속해서 작성하는것은 용량, 노력 부분에서 모두 손해라고 생각했다.
방법을 찾아보던 도중, lambda 함수에서 라이브러리를 직접 업로드해 사용하는 방식과 다르게 AWS lambda layer를 사용하면 공통 라이브러리를 모든 lambda 함수에서 참조해서 쓸 수 있다는것을 발견했다.

구현에 필수적인 라이브러리들과, crawling_INUmenu.py 이렇게 라이브러리들을 알집으로 압축하여 레이어에 업로드만하면 되는데,,, 업로드하게되면 해당 파일들이 lambda의 리눅스 디렉터리 /opt에 위치하게 된다.
그리고 lambda 함수에서 해당 라이브러리를 사용하려면, 정해진 폴더명에 정확히 압축해서 레이어로 올려줘야 오류가 나지 않은 상태로 import에 성공하게된다.
장장 몇 시간을 ,,
s3에 라이브러리 업로드(10mb가 넘어가는 라이브러리는 AWS s3를 이용해 업로드해야함) - 레이어 만들기 - 함수에 레이어 적용 - import 시도 - 실패
하며 결국 성공했다.
이 때 주의해야 할 점들을 실패를 통해 알게 되었다.
사소하지만 주의하지않으면 계속해서 실패하는 내용으로, 이 글을 본 사람들은 lambda에 적용할 레이어를 시간낭비없이 만들길 바라며.. 작성한다.
1. 알집으로 라이브러리를 압축하면, 최상위 디렉터리는 무시된다.
lambda 함수에서 파이썬 라이브러리를 import 하려면, 라이브러리들은 /opt/python 하위에 위치해야 한다.
위에서 말했듯이 레이어에 zip 파일을 업로드하게되면, /opt 디렉터리에 해당 파일들을 압축을 풀어준다고 생각하면 된다.

해당 그림과 같은 상태에서 LIb 폴더에서 python 폴더를 압축하면된다. 윈도우 환경에서 해당 라이브러리를 압축하려면, 라이브러리들을 python/python/라이브러리들 과 같은 경로상에 위치하고 압축해야 압축파일상에서 python/라이브러리들 과 같이 압축되게 된다.
python 폴더 하위에 라이브러리들이 있는것이 아닌, 라이브러리들만 압축해서 올려버리면 lambda에서 해당 라이브러리들을 인식하지 못한다.
ps. 알집말고 7-zip 같은 프로그램을 사용했다면 달랐을까 싶다..
2. 파이썬에서 다른 파일을 import해서 사용하려면, 해당 파일의 이름에 괄호같은 특수문자가 있어서는 안된다.
lambda data용, csv 파일 만들기용 코드들이 내용은 같지만 출력형식만 달라 괄호를 이용해 코드 파일들을 관리했는데.. 파일에 괄호가 있으면 import가 정상적으로 되지 않는다.
내가 작성한 파이썬 코드의 파일명 : crawling_INUmenu(lambda_data).py
ex ) import crawling_INUmenu(lambda_data) -> 실패...
오류 코드는 Syntax 오류였던것 같다.. 문법 오류
기본적인 내용들이지만, 오류 코드가 그저 Syntax 오류라고 뜨기 때문에 문제를 찾아내는데에 많은 시간이 소요됐다 ..
이번에는 코딩을 배웠다기 보다는 AWS lambda 사용법을 배우는 느낌이였다.
위 두가지에서 공통적으로 발생한 오류코드는
runtime.usercodesyntaxerror syntax error in module 'lambda_function'
3. 프로젝트내에 존재하는 Lib/site-packages 폴더를 압축해서 올리면 터진다.
lambda에서 python 기본 라이브러리들을 이미 제공하고 있는 상태에서, 기본 라이브러리를 포함한 site-packages를 압축해서 올려버리면 충돌인지,, 오류가 난다.
따라서 프로젝트에서 사용한 라이브러리들을 특정 폴더에 따로 다시 다운로드 받은 후 압축해서 올려야한다.
오류코드는 File "/var/lang/lib/python3.7/site.py", line 168, in addpackage 와 같이 떴다.
이렇게 오류들을 고치고, 지난번에 이어서 추가된 내용들
먹었던 메뉴 저장을 위해, 음식들의 이름을 엔티티화 시켜서 봇에게 알려줄 필요가 있었다.
ex) 나 오늘 제육덮밥 먹었어
와 같은 발화가 봇에 전달된다면, 엔티티에 제육덮밥이 없을 경우 메뉴로 인식하지 못하기 때문.
from bs4 import BeautifulSoup # 크롤링을 위해 bs4 라이브러리 사용 from urllib.request import urlopen import pandas as pd today_menu_list = [[[], [], [], [], []]] all_menu_list = [] menuTime = [] day_list = ['월','화','수','목','금','토','일'] tday = "" for i in range(6): # 첫번째 인덱스를 요일, 두번째 인덱스를 메뉴 시간, 세번째 인덱스를 메뉴 시간별 세부 메뉴를 가진 3차원 배열 line = [] all_menu_list.append(line) for j in range(5): line = [] all_menu_list[i].append(line) def find_td(selected_menu, result_list,real_index): index = 0 for menu_sub_list in selected_menu: # select는 상단의 코드에서 복수의 td들을 ResultSet(일종의 List형태)로 가져오므로, 반복문을 통해서 각각의 요소들을 get_text()로 처리해줘야함 oneday_menuplan = menu_sub_list.get_text().split('\n') # 한칸에 모든 메뉴가 \n으로 나누어져있음 for j in range(len(oneday_menuplan)): if (oneday_menuplan[j] is '\r' or # 메뉴가 게재된칸에는 가격정보와 제공시간이 적혀있으므로, 메뉴만 얻기위해 예외처리 oneday_menuplan[j][0] is '*' or oneday_menuplan[j][0] is '[' or oneday_menuplan[j][0] is '(' or oneday_menuplan[j][0] is '❝' ): break elif oneday_menuplan[j][0] is '<': # <즉석조리기기>칸의 라면 메뉴들을 가져오기위한 예외처리 continue else: if '국밥' in oneday_menuplan[j]: # 국밥칸에서 칼로리 정보를 제외하고 메뉴 이름만 가져오기위한 예외처리 result_list[index][real_index].append(oneday_menuplan[j][:4].strip()) else: result_list[index][real_index].append(oneday_menuplan[j].strip()) index += 1 url = "https://www.uicoop.ac.kr/main.php?mkey=2&w=2&l=1" html = urlopen(url) soup = BeautifulSoup(html, "html.parser") # 원하는 태그 정보를 뽑아줄 bs4 인스턴스 생성 index = 0 index1 = 0 for tr_menu in soup.find(id='menuBox').find_all('tr'): # menuBox라는 이름을 가진 테이블에서 한줄씩 뽑아냄 not_today_menu = tr_menu.select('.din_list') today_menu = tr_menu.select('.din_lists') menutime_tr = tr_menu.find(class_ = 'corn_nm') day = tr_menu.find(class_ = 'din_mns') if day: tday = day.get_text().strip()[:1] short_date = int(day.get_text().strip()[3:8].replace('/','')) print(tday) print(short_date) if menutime_tr: menuTime.append(menutime_tr.get_text()) if not_today_menu: # 찾은 내용이 있을 경우 find_td(not_today_menu, all_menu_list, index) index += 1 if today_menu: find_td(today_menu, today_menu_list, index1) index1 += 1 for i in range(len(day_list)): if tday == day_list[i]: all_menu_list.insert(i,today_menu_list[0]) break all_menu_clist = [] for i in range(len(all_menu_list)): for j in range(len(all_menu_list[i])): for k in range(len(all_menu_list[i][j])): temp = all_menu_list[i][j][k] all_menu_clist.append(temp) menu_df = pd.DataFrame(all_menu_clist) menu_df.to_csv("menu.csv", header=False, index=False)지난번에 작성한 크롤링 코드에서, 모든 메뉴들을 all_menu_list에 집어넣고 pandas를 이용해 dataframe화 -> csv 파일로 저장하는 내용만 추가했다.
그후, 카카오 빌더에서 제공하는 엔티티 업로드 기능을 이용해 새로운 엔티티로 추가시켰다.
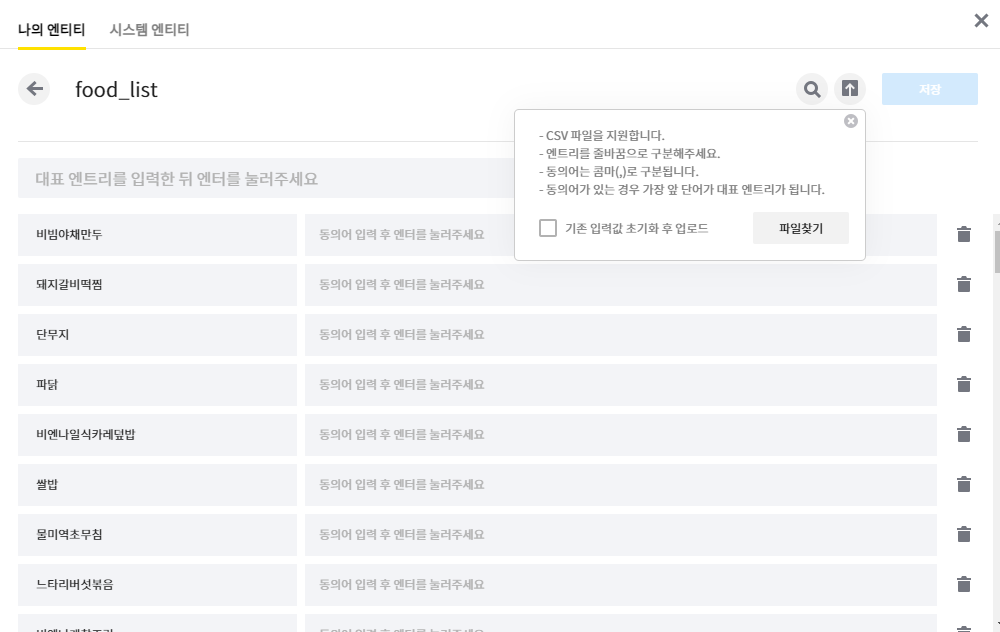
엔티티 -> 나의 엔티티 -> 엔티티 업로드 화면 
이후 발화에서 해당 메뉴들을 입력하면, 엔티티로 인식되는것을 확인 할 수 있었다.
지금 내용까지가 7월7일에 했던 내용들이다. 이번 게시글에 오늘 한것들까지 포함해서 작성하려고 했지만, 너무 길어지는 관계로 따로 포스팅하려고 한다.
'App' 카테고리의 다른 글
AWS Lambda 실시간 로그 사용하기(Cloud watch) (0) 2021.07.15 카카오톡 인천대학교 학식봇 만들기(AWS Lambda) - 8 (0) 2021.07.12 카카오톡 인천대학교 학식봇 만들기(AWS Lambda) - 6 (0) 2021.07.06 카카오톡 인천대학교 학식봇 만들기(AWS Lambda) - 5 (0) 2021.07.05 카카오톡 인천대학교 학식봇 만들기(크롤링) - 4 (0) 2021.07.02